When I was first trying to figure out what topics to cover in this series, I started off by doing what any developer would do: I asked the internet, of course!
Well, to be a little more specific, I started off by googling for algorithms that I had heard about before but didn't understand at all and wanted to learn more about. However, I quickly realized that I was going to have to work backwards – that is to say, I was going to go back to the beginning, and fill in the gaps of all of the things that I didn't know. I had to learn the fundamentals and go back to the very basics before I could really wrap my head around any of the super complex algorithms that I really wanted to learn about.
One of the things that you'll notice when looking at introductory CS courses and their syllabi is that everything, at least for the most part, is taught in the context of efficiency. Data structures and their traversal algorithms are explained in the context of how fast they are, how much time they take, and how much space you need to run them. So far, I've been only skimming the surface of space time complexity. When we learned about linked lists, we inadvertently stumbled upon Big O notation. Just in case you need a quick refresher (I know I do!), Big O notation is a way to express the amount of time that a function, action, or algorithm takes to run based on how many elements we pass to that function.
Here's the thing, though: in the context of linked lists, we only scratched the surface of Big O notation. There's a whole lot more to Big O than just constant and linear time. There are plenty of different functions to describe how well, how quickly, and how efficiently an algorithm runs. And it's time for us to dig a little deeper into one of those functions – one that I've kind of been avoiding thus far.
Not to worry, though! Now that we know about tree data structures and binary searches, we have all the right tools in order to finally learn about this function.
But…what exactly is this function I keep talking about? Why, it's a logarithmic function, of course!
Breaking down binary searches
Binary search is easy to spot once we understand it. On a very basic level, it looks something like this:
- Make sure your data set is sorted.
- Find the middle element in the data set, and decide whether it is larger or smaller than the element that you're looking for.
- Eliminate half of the data set as a possibility, and keep repeating this until you're down to a single element.
The beauty of a binary search – and applying it to a binary search tree – is the simple fact that with each step that we take in traversing the tree, we eliminate half of the elements that we have to search through. In fact, this simplicity is what makes binary trees so powerful: in the process of narrowing down the search set, we also remove half of the search space.
But is it efficient? An even better question: just how efficient is it?
In order to understand efficiency, we have to think about binary search in the context of orders of magnitude. Another way to think about this is by answering the question:
How does our algorithm for searching for a single element start to change as our data set grows? Does it take more time? Do we have to do more work?
When traversing a binary search tree (or even simply performing a binary search on a sorted array), what we're the most concerned with is how many steps we have to take to get down to a single element. And why is this? Well, this comes from the fact that binary search always ends up with us at a single element: it could be the element that we're searching for, or it could be the element that's the closest in value to the one that we're searching for (in which case, we could easily determine that the element we're looking for isn't even in the tree!). In both cases, we end up having split our data set in half enough times that we're down to only one item, and we can't split that any further, which means that our search is officially done!
So, that's what we'll watch for – how many steps we have to take until we get down to a single element. Let's play around with binary search on different-sized data sets and see if we can find a pattern.
We'll start with 2 elements. Okay, this is pretty easy. We don't even need to really sketch it out. When we only have two elements, it takes us only one step of splitting our data, and then we're down to just one element.
Now, let's grow our data set some more. Remember that if we want to search on a binary search tree, the tree has to be balanced; this means that if we want to add another layer to our tree, the number of nodes is going to grow exponentially. So, we'll have to try this experiment out in different scenarios: with 2 elements, 4 elements, 8 elements, 16 elements, and then 32 elements.
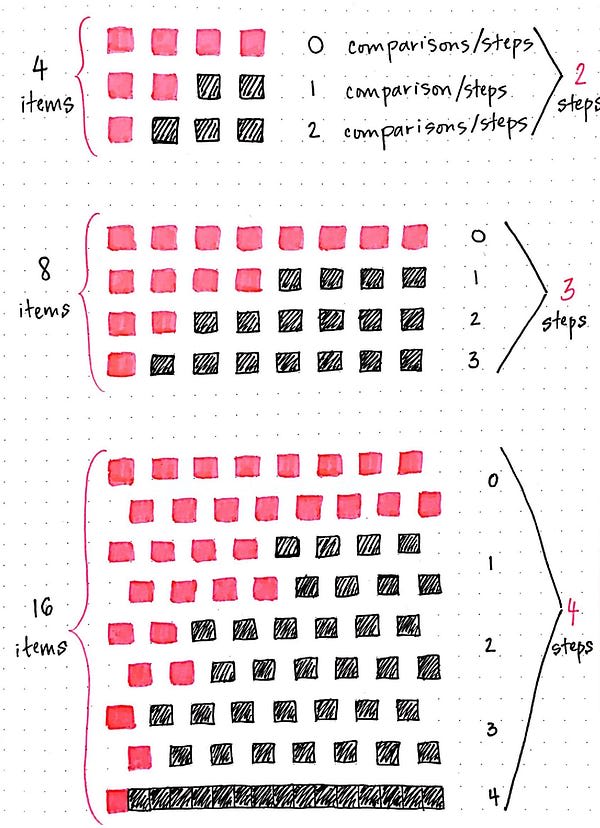
Okay, so how about 4 elements? I have a hard time keeping things in my head, so let's use the drawing to keep track. It looks like when we have 4 elements, we have to take 2 steps: the first step splits our data set into 2 items that we ignore, and 2 items that we'll split once again.
So, what if we make this even bigger? What happens if our data set is 8 items? Well, it's nearly the same as 4 items, right? But with one extra step, where we split 8 items into 4. It seems like when we have 8 items in our data set, we need to take 3 steps to get down to just one item left.
Alright, let's draw this out one more time: with 16 items! Maybe you can even guess how many steps it will take without looking. Using binary search, it will take us 4 steps to split 16 items down to just one single element.
Okay, now with 32 elements. (Just kidding. That's a lot of little pink squares!)
We could probably keep drawing out all of the different sizes of binary search trees as it grows exponentially, but that would start to get a bit unwieldily! So, instead of drawing out how many steps it would take with 32 elements, let's try to look for a pattern. I've got a feeling there's got to be a pattern in there somewhere!
Let's rearrange the information that we've gleaned from this exercise so that it's easier to see what's going on. Don't worry if this looks weird at first – I promise it's exactly the same information, just rewritten in a different way:
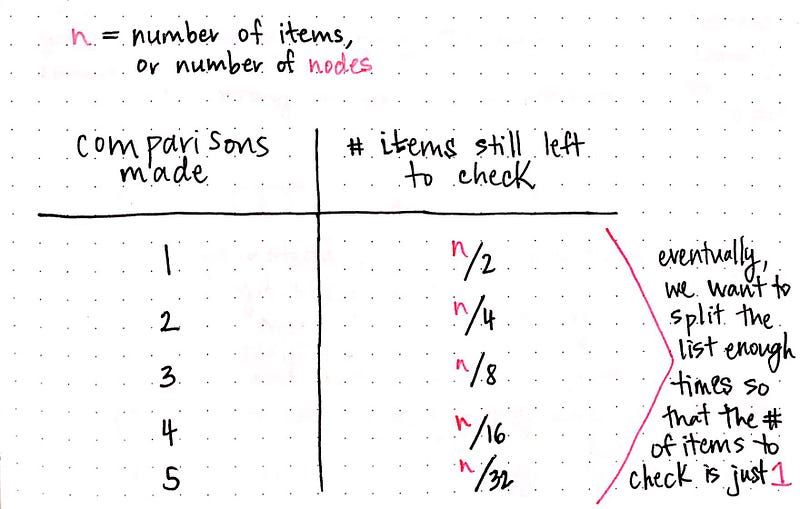
In the table above, n represents the total number of items or nodes (in a tree). Based on the exercise of sketching out different scenarios of data sets we did earlier, we can substitute any of those numbers in for n, and our drawing should still hold true. For example, when we had 16 items, it took us 4 steps, because 16/16 is the only situation when we're left with just one single item left to check.
So, how can we generalize this? Well, just from looking at the right column of this table, we can see one pattern immediately: take a look at each of the denominators in the fraction that's used to determine how many items are left to check. They're doubling each time: 2, 4, 8, 16, and so on. Interesting.
But it gets even more interesting when we look at the left column in the table: the comparisons we had to make – in other words, how many steps we had to take to get down to just one element. There's a pattern there, too. They're increasing incrementally, by just one.
However, if we look at them side by side, we can start to see yet another pattern emerge:
If we raise 2 to the power of the number of steps in the left column, we get the denominator of the fraction that represents the number of items still remaining to be checked in the right column.
Now, without even drawing out 32 items, we can guess how many steps it would take: 2âµ is equal to 32, so we can determine that if n is equal to 32, it will take us 5 steps to narrow down our search set to just one single item.
Hooray! We've just naturally stumbled upon a logarithm in the wild! Now, let's figure out what on early that actually means.
Finding the rhythm of a logarithm
If you're thinking, “Hey wait, a logarithm is just an exponent!”…well, you're right. Logs are just exponents, but flipped, in a way. A logarithm is the power to which a number must be raised in order to equal another number. Another way of thinking about logarithm like log a x is by answering the question:
To what power (exponent) must the variable a be raised to in order for me to get x?
Cool, that's great I guess. But what do logarithms have to do with binary searches, exactly? Well, a whole lot, as it turns out! The best way of illustrating this is by looking at our binary search algorithm in a different perspective. Let's go back to our example from earlier – we have 16 items, and we want to binary search through this data set until we're left with just one item.
As we start getting into the nitty gritty math behind this, keep in mind that important question that we're the most concerned with here is this: how many times did we divide our collection of items in half before we were down to just one item?
When we have 16 items, we have to divide our data set in half four times until we're down to just one item. We divide 16 by two once, then divide 8 by two, then 4 by two, and finally 2 by two.
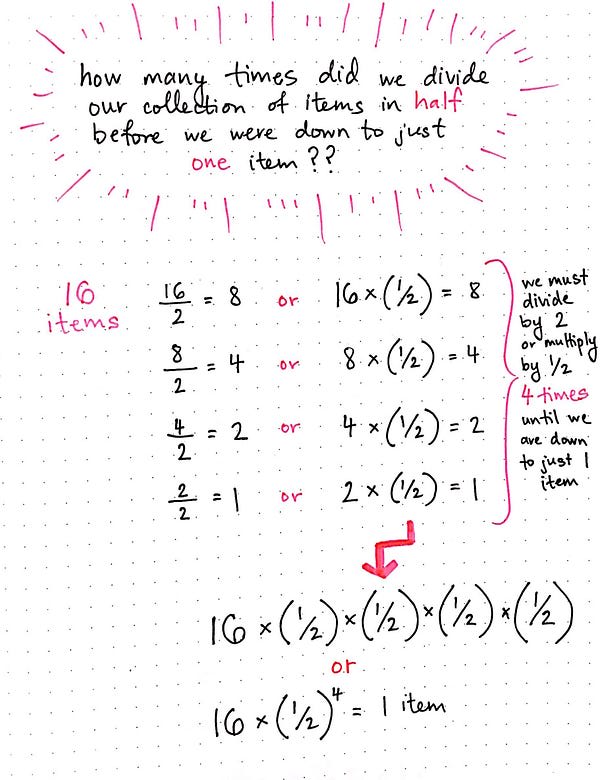
So far so good, right? We already know this to be true, since we wrote and drew it all out! But there's another way to write this. Dividing by two is the same as multiplying by 1/2. Which means that we could also that say this: when we have 16 items, we have to multiply our data set by 1/2, four times, until we're down to just one item.
Okay. We should clean this up a little bit. Let's rewrite it.
Since we know that we need to multiply by 1/2 four different times, we could also say that we need to multiply 16 x (1/2)â´ until we're down to just one single item.
Okay! Now we're getting somewhere. Before we go any further, let's just make sure we did that right. (Also, I want to prove to you that I'm not doing any weird math magic here – the numbers still check out!)

Okay, cool. Still with me? Good.
Now, we're sure that this works for the number 16, which is to say: this works for when we have a dataset of 16 items. But, we're programmers! Let's abstract this so that we have a formula that we can can apply to any size dataset.
Instead of 16 x (1/2)â´ = 1, let's use some more generic variables. We'll use n in place of 16, to represent the total number of items. And instead of (1/2)â´, we'll replace 4 with x, where x represents the number of times we need to divide n in order to get to one single item at the end.

Nice! We used some simple algebraic rules and rewrote our abstraction! What did we end up with? A logarithm! Which we could read as: n equals 2 to the power of x, or in other words, log 2 of n is equal to x.
Remember that question from earlier? To what power (exponent) must the variable a be raised to in order for me to get x? In this case, we could say that we need to raise 2 to the power of however many times we need to divide our dataset in half. Or, another way to put it: the number of total elements is equal to 2 to the power of steps we need to take to get down to one element.
I think it's safe for us to revisit our table from earlier and add in our abstraction:

Awesome – we now have a logarithmic function to help us determine how many maximum number of comparisons we'd need to make as the size of our dataset (or binary search tree) grows in size.
Meet O(log n), your new best friend!
We've diverged quite a bit from where we started, haven't we? We've done some drawing and a lot of math, but…what on earth does this have to do with computer science?
Well, logarithms play a big part in how efficient an algorithm is. Remember what we set off to find out about initially? Just how efficient is a binary search?
Now that we have seen firsthand how efficient a binary search is by drawing it out and by doing the math behind it, we hopefully can see that a binary search algorithm is an operation that is logarithmic, and runs in logarithmic time.
I really like the way that Dave Perrett describes logarithmic algorithms in his blog post:
Any algorithm which cuts the problem in half each time is O(log n).
O(log n) operations run in logarithmic time – the operation will take longer as the input size increases, but once the input gets fairly large it won't change enough to worry about. If you double n, you have to spend an extra amount of time t to complete the task. If n doubles again, t won't double, but will increase by a constant amount.
This is exactly what we stumbled upon so naturally when we were breaking down binary search earlier! Each time we doubled our tree or data set, we only had to take one extra step to find an element. This is why searching through 32 elements took only one maximum extra comparison than searching through 16 elements – the algorithm we were using was logarithmic, and was cutting our problem in half each time we searched.
This is one of the reasons that binary searches are so popular in computer science – they are super efficient for datasets that grow arbitrarily large.
But there's another reason that logarithms are interesting to us as programmers. They are the inverse of exponential functions, which hopefully make you shudder, because exponential algorithms are bad news!

An exponential function grows the number of operations that we have to do as our data set grows on an exponential level; a logarithmic function, on the other hand, is the inverse. It grows logarithmically. We can see how these two functions are the inverses of one another when we plot them on a graph and compare them to a linear function, which takes constant time.
But as programmers, we're not really plotting graphs or thinking about any of this all that much. Those of us who do need to think about binary search or binary search trees probably already know by heart that the efficiency of a binary search algorithm is O(log n).
The only time we'd probably really ever need to think about this is in the context of Big O Notation. The team over at Big O Cheatsheet has a beautiful graph that shows how O(log n) compares to a bunch of other algorithms. Here's a less pretty, but more simplified version of that graph that compares O(log n) to the other algorithms we've looked at in this series: O(1), or constant time, O(n), or linear time, and O(n²), or quadratic time:

Generally speaking, O(log n) is a good algorithm to have on your side. And even if you never have to think about it again, now you know how it actually works!
Resources
Do you love to log? Good news – there's still so much to learn and so much that I couldn't cover in this post! If you want to learn more, you might enjoy these resources.
- CompSci 101 – Big-O Notation, Dave Perrett
- Logarithmic Functions and Their Graphs, Professor James Jones
- Big-O Complexity Chart, Big O Cheat Sheet
- The Binary Search, Brad Miller, David Ranum
- Log N, Matt Garland





Top comments (3)
It’s a really friendly and well written arcticle for such a scary theme (for me at least). I’ve been looking at those big O notations for some time, and for the first time ever it did make some sense. Thank you!
What an awesome article! Finally someone explained it to me the way I could fully grasp it. Thank you so much for the text and the entire series as well!
YAY! I'm so glad to hear it. Logarithms took me awhile to understand, too. I'm happy that you were able to get it much faster than I did ☺️